
NOTE本文由 Google Gemini DeepResearch 辅助完成。
现代计算科学的演进历史中,图形用户界面(GUI)底层的架构设计始终处于不断地打破与重构之中。随着云计算的纵深发展、远程办公常态化以及跨平台虚拟化技术的爆炸式增长,系统工程师与底层开发者面临着前所未有的挑战:如何跨越物理网络限制、甚至跨越不同的指令集架构(如 x86_64 与 ARM64),实现高保真、低延迟的图形渲染与交互。特别是当计算平台向 Apple Silicon(M 系列芯片)这种采用统一内存架构(UMA)的设备迁移时,如何在严格的沙箱环境中为 Linux(如 Ubuntu)虚拟机提供底层的 3D 硬件加速,成为了业界公认的核心技术壁垒。
要系统性地解答这一难题,必须追本溯源。本综述将以客观、严谨的学术探讨口吻,深入剖析图形显示技术的三大核心维度。首先,系统梳理 Linux、Windows 与 macOS 三大操作系统底层图形架构的设计哲学与渲染管线;其次,横向对比跨越物理设备的“远程桌面”技术流派及其数据交互原理;最后,聚焦于现代 Apple Silicon 架构,深度解析指令转译开源方案与 Apple 原生半虚拟化技术在解决本地虚拟机图形加速难题上的底层博弈与工程实践。
第一部分:操作系统 GUI 底层架构巡礼
任何跨平台图形交互或虚拟化渲染的难点,从根本上讲,都源自源端与目的端操作系统底层图形渲染管线的“阻抗不匹配”。各大操作系统基于其独特的历史背景与生态诉求,演化出了截然不同的视窗架构。
1.1 Linux:从 X11 的“网络透明”到 Wayland 的“本地合成”
Linux 及类 Unix 系统的图形架构演进,是一场关于“网络透明性”与“极致本地渲染效率”之间的深刻反思与重构。
X11 架构与 C/S 模型:历史的馈赠与现代的包袱
X Window System(通常被称为 X11)诞生于 1984 年的麻省理工学院,其核心基石是客户端-服务端(C/S)模型与网络透明性 。在 X11 的设计语境中,存在着极为严格的角色划分:“X Server”是直接掌管本地显示器、键盘、鼠标等硬件资源的进程,而“X Client”则是实际运行并需要显示画面的应用程序。这种架构的精妙之处在于,Client 可以运行在本机,也可以运行在网络中的另一台大型机上。Client 仅需通过 X 协议向 X Server 发送抽象的绘图指令(如绘制多边形、渲染字体),由 X Server 统一与显卡交互完成最终渲染。

然而,随着现代计算环境的发展,这种架构暴露出严重的性能与安全瓶颈。首先是渲染路径的冗长问题。现代应用程序早已不再依赖 X Server 提供的高级绘图基元,而是倾向于使用 OpenGL、Vulkan 或 Cairo 等现代图形 API 在客户端本地完成全部的 UI 渲染。在此模式下,应用程序生成像素缓冲后,需将其传递给 X Server,X Server 再将其交给独立的窗口管理器(Window Manager)计算位置,最后再交回 X Server 进行合成与输出。这种反复的进程间通信(IPC)与上下文切换,导致了显著的延迟与较高的 CPU 开销 。
其次是结构性的安全缺失。X11 协议在设计之初默认处于一个相互信任的网络环境中,这意味着任何接入 X Server 的 Client 都可以全局监听键盘输入事件(Keylogging),或者无限制地读取其他窗口的内容(Screen Scraping)。在现代操作系统的沙箱安全理念中,这种全局暴露的设计是难以接受的 。
Wayland:追求极致渲染效率的设计哲学
为了彻底解决 X11 的结构性顽疾,Wayland 协议于 2008 年应运而生。Wayland 的核心哲学是消除所有不必要的中间层,将显示服务器(Display Server)与合成器(Compositor)合二为一 。
在 Wayland 架构中,应用程序(Client)利用现代图形 API 直接在自身分配的显存缓冲区中完成渲染。渲染完毕后,Client 仅仅是将该缓冲区的句柄(通常通过 Linux 的 dma-buf 机制)通过 Unix Domain Sockets 传递给 Wayland Compositor 。Compositor 接收到所有窗口的缓冲区句柄后,直接利用底层 Linux 内核的 DRM(Direct Rendering Manager)和 KMS(Kernel Mode Setting)子系统将画面提交给屏幕显示 。

这种去中心化的设计带来了革命性的优势。其一,实现了真正的“零拷贝”(Zero-copy)渲染,去除了 X11 中繁杂的内存复制步骤,极大地降低了渲染延迟并原生消除了画面撕裂(Tearing)现象 。其二,带来了原生的安全隔离机制。在 Wayland 中,Compositor 充当了绝对的仲裁者,应用程序仅在获得焦点时才能接收输入事件,且严格禁止跨窗口读取像素,屏幕共享等操作必须通过 XDG Desktop Portal 等显式协议并获得用户授权后方可执行 。其三,得益于 GPU 缓冲区的直接复用,系统在日常空闲与动画过渡时的 CPU 唤醒次数大幅减少,从而为便携式 Linux 设备带来了可观的电池续航提升 。

1.2 Windows:DWM 机制与 DirectX 的深度融合
Windows 系统的图形架构在 Windows Vista 时代经历了一场剧变。微软引入了桌面窗口管理器(Desktop Window Manager, DWM),并将其与底层的 DirectX 及 WDDM(Windows Display Driver Model)驱动模型进行了深度融合 。
DWM 的离屏合成机制
在 Windows XP 及更早期的系统中,应用程序(基于 GDI/GDI+)默认会直接将像素数据写入显卡的单一前台显示缓冲区。这种被称为“堆叠窗口管理器”的模式存在致命缺陷:当一个窗口被拖动或底层窗口被重新暴露时,操作系统必须向应用程序发送 WM_PAINT 消息要求其同步重绘。如果应用程序响应迟缓,屏幕上就会残留大量的视觉残影 。
DWM 的引入将 Windows 彻底推向了合成式桌面(Compositing Desktop)时代。开启 DWM 后,应用程序不再被允许直接写入屏幕缓冲区。相反,无论是基于 GDI 还是 DirectX 的程序,其渲染输出都会被重定向到系统为每个窗口独立分配的离屏内存表面(Off-screen Surface)中 。dwm.exe 进程随后作为统一的合成引擎,在幕后将所有离屏表面组合成最终的桌面图像,并一次性推送到屏幕上 。这不仅彻底消除了重绘残影,还使得透明毛玻璃(Aero Glass)、动态缩放、3D 翻转等高级视觉特效成为可能 。
内核级 DirectX 绑定与 WDDM 调度
DWM 的高效运行离不开底层 WDDM 架构的支撑。现代 Windows 的图形子系统跨越了用户态与内核态的边界:
- 用户态 API:
dcomp.dll(DirectComposition API)提供了一套基于 COM 的接口,允许应用程序构建复杂的视觉树;而dwmcore.dll则是执行实际桌面合成的核心引擎 。 - 内核态调度:
win32k.sys负责编排窗口指令并管理内核级对象数据库,而dxgkrnl.sys(DirectX 图形内核子系统)则负责极其核心的视频内存管理与 GPU 抢占式任务调度 。
这种设计赋予了 DWM 极高的执行优先级与硬件资源掌控力。DWM 能够精确感知不同窗口的 Z 轴层级,执行遮挡剔除(Occlusion Culling),从而避免为不可见的窗口浪费 GPU 算力 。更重要的是,DWM 底层全面拥抱 DirectX 渲染管线,系统级色彩管理(如将各个应用程序的色彩空间转换为线性 CCCS 格式再进行混合,以支持 HDR 输出)也在 DWM 与显示内核的协作下高效完成 。
1.3 macOS:Quartz 视窗系统与 Metal 的软硬一体闭环
与 Linux 的开源离散生态以及 Windows 沉重的历史包袱不同,Apple 对 macOS 的图形管线拥有绝对的控制权。其图形系统的核心基础被称为 Quartz,而在向 Apple Silicon 演进的过程中,Metal API 的全面普及使得 macOS 实现了极其纯粹的软硬一体闭环架构 。
Quartz Compositor 与系统事件循环
在 macOS 中,肩负显示服务器与合成窗口管理器双重职责的组件是 Quartz Compositor,其在系统进程池中以高度活跃的 WindowServer 进程形式存在 。
macOS 应用程序的图形流转路径极为统一。开发者通过 AppKit 或 SwiftUI 构建界面,这些界面元素在底层最终被转化为 Core Animation 框架中的 CALayer 树 。应用程序在自身的进程空间内,利用 Metal 图形 API 将复杂的视图(包括圆角、阴影、矢量文本)光栅化,并输出到被称为 IOSurface 的底层数据结构中。IOSurface 是一种专门为跨进程共享显存而设计的极其高效的内核对象 。 随后,这些 IOSurface 的引用通过 Mach IPC(苹果内核的高性能消息传递机制)被迅速投递给 WindowServer。WindowServer 接收到所有应用程序的图层后,执行全局的 Z 轴深度排序、Alpha 混合以及全局滤镜处理,最终与显示器的垂直同步信号(V-Sync)对齐,输出完美流畅的帧 。
Metal API 与统一内存架构的极致协同
macOS 图形系统的真正壁垒,在于 Metal API 与 Apple M 系列芯片统一内存架构(UMA)的深度结合。Metal 是 Apple 推出的低开销图形与计算 API,它摒弃了 OpenGL 繁冗的状态机检查,使用基于 C++ 的 Metal Shading Language(MSL)直接对 GPU 硬件进行细粒度控制 。
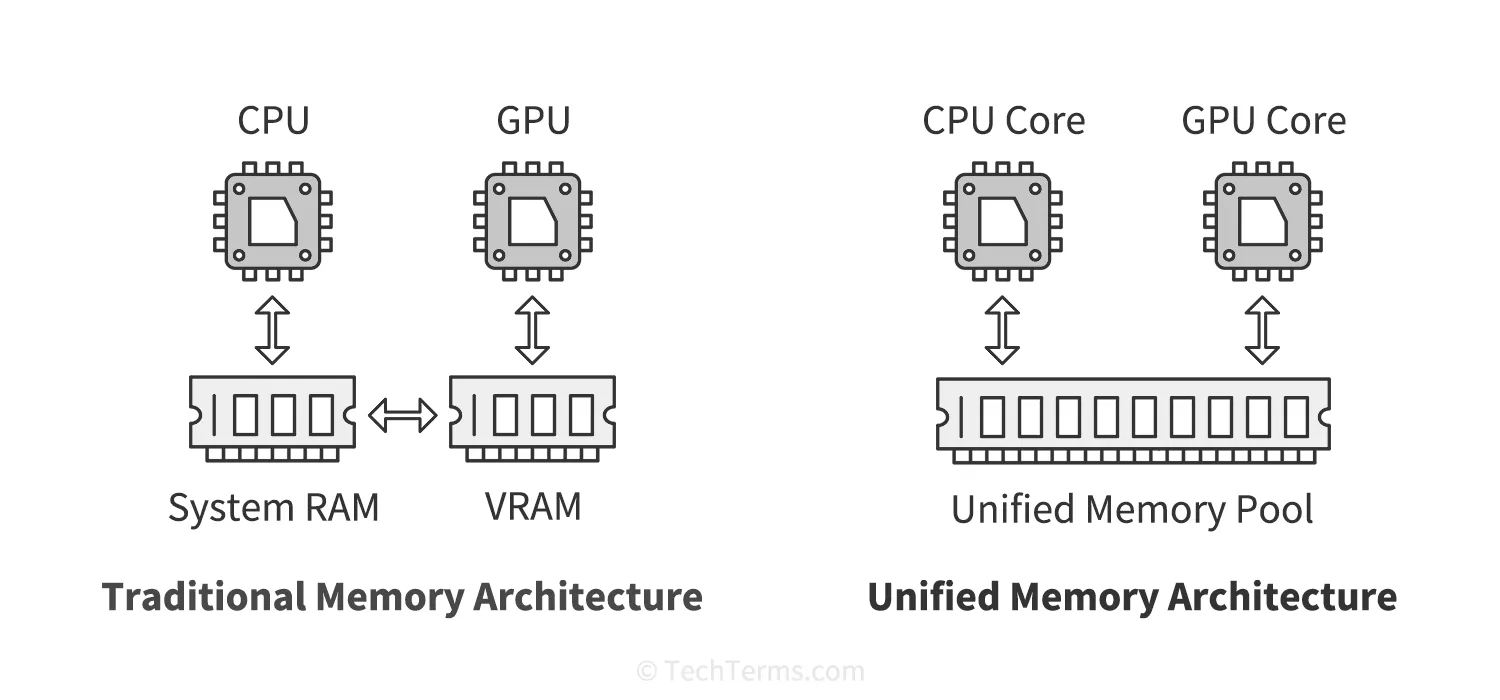
在传统的 x86_64 配合独立显卡的架构中,内存与显存是物理隔离的,数据必须经过 PCIe 总线进行昂贵的拷贝。但在 Apple Silicon 的 UMA 架构下,CPU 核心、GPU 核心以及神经网络引擎(NPU)共享同一块高带宽物理内存池 。这意味着应用程序在内存中生成的 IOSurface,在移交给 WindowServer 进行合成、直至被 GPU 渲染的整个生命周期内,不存在任何物理意义上的数据移动 。这种“零拷贝”机制赋予了 macOS 在处理海量窗口并发、高分辨率缩放以及极速动画响应时,不仅毫无卡顿,更能将系统功耗压制在令人惊叹的低位 。
底层架构总结:跨平台显示的技术壁垒
| 操作系统 | 核心显示架构 | 渲染与合成机制 | 显存/缓冲交互特征 | 架构设计哲学 |
|---|---|---|---|---|
| Linux (Wayland) | Wayland Compositor | Client直绘,Compositor仅负责合成,去除中间X Server | dma-buf 文件描述符传递,去中心化零拷贝 | 极致隔离、安全优先、贴合现代 GPU 渲染逻辑 |
| Windows | DWM (Desktop Window Manager) | 强制所有应用渲染至离屏表面,由 DWM 统一硬件合成 | 深度依赖 WDDM/DirectX,混合 GDI 与 D3D 缓冲 | 强兼容性优先,内核级 GPU 调度,复杂特效支持 |
| macOS | Quartz Compositor (WindowServer) | Core Animation 抽象图层,通过 Mach 端口转移上下文 | IOSurface 跨进程共享,基于 M 芯片 UMA 物理级零拷贝 | 软硬一体封闭闭环,绝对的极简流程与能效比优先 |
通过对比可知,这三大生态在数据流转、进程隔离边界、内存寻址模型以及驱动抽象层级上存在巨大的结构性差异。当系统工程师试图在异构环境间进行显示输出(例如从 Windows 远程连接 Linux,或在 macOS 上虚拟化运行 Ubuntu)时,必须通过极其复杂的协议或底层转译框架来弥补这些鸿沟。这正是我们接下来探讨的远程桌面协议与本地虚拟化技术所要攻克的核心壁垒。
第二部分:“远程桌面”技术的三大流派
当我们需要跨越物理设备的边界,通过带宽受限、丢包不定的广域网或局域网进行图形交互时,“远程桌面”技术成为了唯一的桥梁。为了适应不同的网络条件、操作系统异构性以及算力限制,远程协议演化出了三条底层数据交互方式截然不同的技术流派。
2.1 指令传递派(RDP):带宽克星与像素级锐利度的王者
RDP(Remote Desktop Protocol) 是微软基于 ITU-T T.128 标准构建的专有远程桌面协议 。与其他截屏式的协议有着本质区别,RDP 的核心机制在于指令抽象传递与对象本地重构。
核心机制与数据流
在 RDP 连接建立后,服务端的操作系统并不会粗暴地将屏幕画面压缩为视频流。相反,RDP 驱动层(如 Windows 的 WDDM 重定向驱动)会直接拦截应用程序产生的底层图形设备接口(GDI/DirectX)调用指令 。

- 抽象指令序列化:服务端捕获到“绘制直线”、“在指定坐标渲染特定字体的字符串”或“填充多边形”等绘图原语(Drawing Orders)后,将这些语义指令打包进入网络协议单元(PDU,如
Demand Active PDU)中传输给客户端 。 - 位图缓存(Bitmap Caching):对于难以用指令描述的复杂图像或频繁使用的 UI 元素(如桌面图标、工具栏按钮),RDP 引入了高级的位图缓存机制(如 Cache Bitmap Revision 3)。服务端将这些微小切块压缩传输一次,客户端收到后将其持久化缓存到本地内存或磁盘中。当屏幕再次需要显示该元素时,服务端只需下发一条极短的引用索引(Index) 。
- NSCodec 压缩扩展:针对 32 位色彩深度的复杂图形,RDP 使用了高度优化的 NSCodec 位图编码扩展进行压缩处理,结合高效的通道分离技术,最大化减少非指令图形的体积 。
优势与最佳场景
由于传输的是绘图指令而非海量像素,RDP 具备极端的带宽压缩比,即使在低于 1 兆(1Mbps)的恶劣网络环境下,依然能保持流畅的交互响应 。 其最无与伦比的优势在于绝对的显示锐利度。由于文本和矢量图形是由客户端设备的 GPU 根据抽象指令进行“原生级”重新渲染的,因此彻底杜绝了视频编码带来的色彩溢出、边缘模糊或色度子采样(Chroma Subsampling)伪影 。对于系统管理员、运维人员,特别是需要长时间注视清晰代码的软件开发者而言,RDP 能够提供零视觉疲劳的顶级办公体验 。
2.2 像素截取派(VNC/RFB):无视底层异构的万能兼容兜底
VNC(Virtual Network Computing) 是基于开源 RFB(Remote Framebuffer) 协议构建的远程显示系统 。它秉持了一种极为务实的设计哲学:不关心操作系统,不拦截高级绘图指令,只在图形管线的最末端——物理显存(Framebuffer)上做文章 。
核心机制与数据流
RFB 协议的交互逻辑基于“脏矩形(Dirty Rectangles)探测与像素块传输”。
- 需求驱动更新:VNC 采用客户端需求驱动的模式。客户端发送
FramebufferUpdateRequest告知服务端自身的视口状态;服务端比对前后两帧的帧缓冲区,找出发生像素改变的矩形区域,并将其封装为FramebufferUpdate消息推送回客户端 。 - 多样化编码算法:面对庞大的原始像素数据,RFB 定义了多种灵活的编码格式(Encoding Types)。例如,当用户拖动窗口时,服务端只需发送一条
CopyRect编码指令,告诉客户端“将屏幕上区域 A 的像素整体平移到区域 B”,从而大幅节省带宽 ;对于静态纯色区域,使用Hextile编码进行矩形切分压缩;而针对复杂图像,则动态切换到结合 zlib 和 JPEG 的Tight或ZRLE高级压缩算法 。
优势与最佳场景
VNC 最大的战略价值在于其绝对的跨平台兼容性 。无论服务端运行的是 Windows Server、极度精简的 Linux 发行版,还是基于 ARM 架构的嵌入式树莓派,只要该系统具备最终的像素输出能力,VNC 就能将画面抓取出来。它无需深入内核去拦截复杂的驱动调用,因此在系统兼容性和稳定性上极具韧性 。 然而,这种简单粗暴的像素传输机制在面对动态画面时显得捉襟见肘。任何大面积的画面刷新(如播放视频或滚动大段网页)都会触发海量的脏矩形更新,瞬间榨干网络带宽并导致严重的画面撕裂与卡顿 。因此,VNC 的最佳适用场景是系统级应急运维兜底、机房服务器初始环境配置,以及对响应速度要求不高的跨异构平台教学演示 。
2.3 硬件视频流派(Sunshine/Moonlight):低延迟与高帧率 3D 的统治者
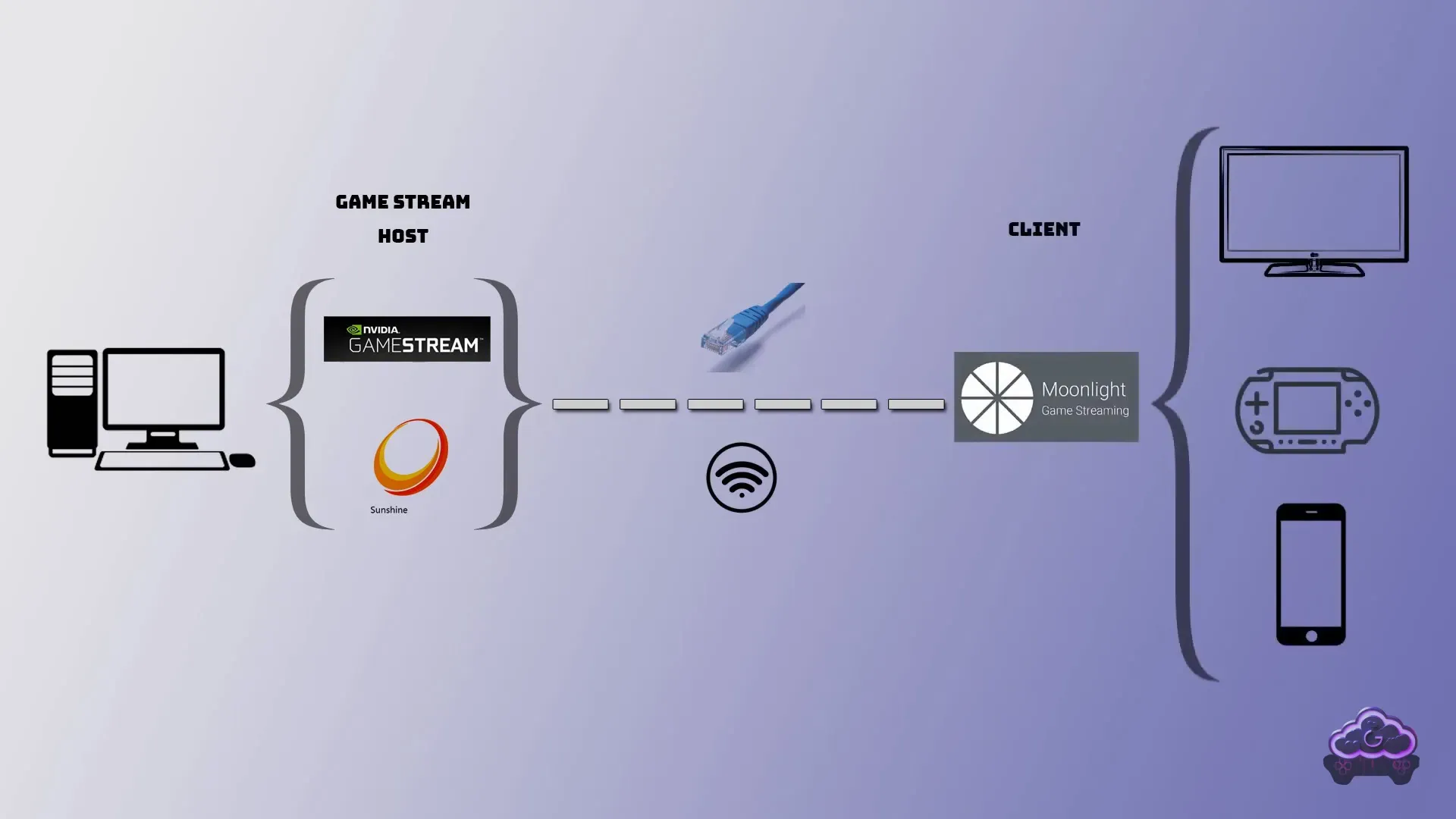
当远程操作进入到云游戏、重度 3D 建模或基于物理引擎(如 Gazebo)的机器人仿真领域时,传统的指令传输与像素切块算法在计算复杂度和带宽占用上双双失效。以开源组合 Sunshine(服务端)与 Moonlight(客户端) 为代表的硬件视频流派,通过引入实时推流架构,彻底颠覆了高负载图形的远程传输体验 。
核心机制与数据流
硬件视频流派的核心思路是将整个桌面视作一场“实时直播”。它将极度密集的计算压力转嫁给了现代显卡内部集成的专用硬件硅片上 。
- 无干预底层画面捕获:服务端(Sunshine)利用现代操作系统提供的极低延迟截屏 API(如 Windows 的 DXGI Desktop Duplication、macOS 的 AVFoundation 或 Linux 下的 KMS/DRM 直接抓取),绕过 CPU,直接从显存中提取合成后的完整画面结构 。
- 专用硬件极速编码:获取帧后,系统立刻将显存指针交给 GPU 上的专有硬件编码器(如 NVIDIA NVENC、AMD AMF 或 Intel QuickSync)。这些固化在硅片上的硬件电路能以不可思议的速度(通常在一到两毫秒内)将巨大的未压缩位图压缩为极致高效的 H.264、HEVC(H.265)或 AV1 视频流 。
- UDP 传输与硬件解码:视频流通过低延迟的 UDP 协议传输,辅以 FEC(前向纠错)算法应对网络丢包 。接收端(Moonlight)同样调用移动设备或 PC 上的硬件解码芯片进行秒级反解还原,确保画面输出。
优势与最佳场景
这一流派在延迟与刷新率表现上拥有统治级地位,是目前唯一能够稳定输出 4K 120Hz、且端到端延迟可控制在 5~10 毫秒(局域网内)的技术方案 。通过配置极高的码率限制(如 100Mbps 以上)并开启 4:4:4 色度子采样(Chroma Subsampling),硬件流派在画质上几乎可以做到与本地直连肉眼无辨的境界 。 然而,其技术限制也同样显著:它对底层的物理显卡硬件存在刚性依赖。如果没有物理 GPU 的专属编码器模块支持,依靠 CPU 软编码(Software Encoding)带来的高延迟与极高系统占用将摧毁一切体验。因此,其极度适用于具备高性能独立显卡或强劲核心显卡的 3D 游戏串流与专业级图形渲染远程工作站 。
远程显示技术综合对比概览
| 核心特性 | RDP (指令传递派) | VNC/RFB (像素截取派) | Sunshine/Moonlight (硬件视频流派) |
|---|---|---|---|
| 数据源基础 | 操作系统底层绘图指令与UI结构树 | 显存末端的最终像素位图 (Framebuffer) | GPU 合成后的完整画面 |
| 压缩与传输策略 | 抽象指令序列化、持久化位图缓存、NSCodec | 脏矩形检测比对、差异像素块压缩 (ZRLE, Hextile) | GPU 硬件视频编码器压制 (NVENC, HEVC/AV1)、UDP 传输 |
| 带宽与网络耐受度 | 极佳 (可在极低带宽下流畅工作,抗网络抖动强) | 较差 (大面积变动时带宽爆炸,低带宽下严重卡顿) | 中等 (需稳定高带宽以维持画质,但高帧率表现最佳) |
| 画质呈现特点 | 文本与矢量图形绝对清晰,无色彩边缘衰减 | 静态画面无损,动态画面帧率低下、易现块状撕裂 | 动态极度连贯,存在极轻微视频压缩伪影(高码率下可忽略) |
| 软硬依赖与生态 | 深度依赖 Windows 内核与远程桌面服务集成 | 无底层依赖,适配一切能输出像素的系统体系 | 刚需宿主机拥有具备硬件视频编码能力的物理 GPU |
第三部分:macOS 图形虚拟化技术对比
在理清了物理网络层面的远程桌面协议后,我们需要将目光投向现代系统工程师面临的最具挑战性的边缘场景:本地异构环境的图形虚拟化。
场景引入与核心难题 当开发者使用一台搭载现代 Apple Silicon(M 系列芯片)的 Mac 时,由于工作所需,必须在本地运行一台基于 ARM64 架构的 Linux(如 Ubuntu)虚拟机。在这个环境中,不存在跨国网络的高延迟,也没有带宽限制;但与此同时,也彻底失去了在 x86_64 时代传统工作站上使用的 VFIO PCIe 显卡直通(Passthrough)技术的可能性。 M 系列芯片采用了高度集成的 SoC 与统一内存架构(UMA),CPU、GPU 固化在同一块物理硅板上,虚拟机管理程序(Hypervisor)无法像剥离独立硬件那样将一块 GPU 切割给虚拟机独占使用 。如果放任 Ubuntu 虚拟机在沙箱内依靠纯 CPU 软件模拟(如 Mesa 的 llvmpipe 驱动)进行光栅化渲染,那么即便只是运行普通的桌面环境,甚至进行基础的 3D 数据可视化,整个系统也会陷入惨不忍睹的卡顿与极高的 CPU 发热之中。 那么,“如何让重重沙箱隔离内的 Linux 系统,安全且高效地穿透边界,调用 Mac 宿主机 M 芯片强大的原生图形与计算 API?” 这成为了业界架构师们必须攻克的技术深水区。目前,这一难题衍生出了两条极具代表性的技术路径。
技术路径一:基于指令序列化与重翻译的开源方案(QEMU/UTM 体系)
在拥抱开源与标准化协议的 QEMU 及前端分支(如 UTM)阵营中,架构师们构建了一套被称为 virtio-gpu 结合 Virgl/Venus 的庞大“翻译管道”。这套管线的核心逻辑在于虚拟设备的抽象介入与指令的逐级解包翻译。
第一跳:virtio-gpu 的虚拟抽象屏障
由于 Linux 虚拟机无法直接接触底层 Apple 硬件,QEMU 在 Hypervisor 层面注入了一个标准化的半虚拟化图形设备——virtio-gpu 。它向 Ubuntu 伪装成一张标准的 PCI 显示适配器。Ubuntu 内核被“欺骗”后,理所当然地加载了与其匹配的 DRM(Direct Rendering Manager)驱动模块 。 此时,当 Ubuntu 内的应用程序或 Wayland Compositor 尝试进行 3D 渲染时,它们产生的调用请求被 virtio-gpu 捕获,打包并序列化,随后通过 Virtqueue(基于共享内存的环形队列)传输,跨越虚拟机沙箱边界,发送到运行在 macOS 宿主态的 QEMU 进程手中 。
第二跳:繁重且极易损耗的管线翻译 (Virgl 与 Venus)
难题的关键在于,Ubuntu 内部应用程序吐出的是标准的 OpenGL 或 Vulkan 图形指令,而 macOS 宿主机经过彻底的底层清洗后,早已弃用 OpenGL 且完全不原生支持 Vulkan,它只认自家的 Metal API 。这就迫使 QEMU 必须在宿主机内存中进行昂贵的语法实时“同声传译”。
- 传统的 OpenGL 翻译(Virgl): 在老旧的实现中,Linux 端的 Mesa
virgl驱动会将应用程序的 OpenGL API 剥离,转化为一种被称为 TGSI(Tungsten Graphics Shader Infrastructure)的中间层二进制表示 。当这些晦涩的指令穿过 virtio 队列到达 macOS 后,由开源项目virglrenderer接收。紧接着,这些请求又不得不进入ANGLE库(一个开源的 OpenGL ES 转译层),经过ANGLE的强行揉捏,再次通过外挂的MoltenVK转换,最终才生成了 Metal 渲染管道指令被喂给 M 芯片 。 这条路线漫长达五层封装(Guest OpenGL → TGSI → virglrenderer → ANGLE → MoltenVK → Metal),每一次的格式反序列化、着色器编译与状态机校验,都带来了严重的性能惩罚。在处理高密度多边形或复杂着色时,进程崩溃是家常便饭 。 - 现代 Vulkan 的序列化通道(Venus): 痛定思痛的开源社区随后推出了基于 Vulkan 的 Venus 协议来重构这座巴别塔 。Venus 的架构哲学更为激进:它将自己定位为一个轻量级的 Vulkan 指令“物流转运层” 。
- 虚拟机端:Ubuntu 内部的 Mesa 驱动(
virtio-vulkan)不再进行复杂的中间层编译,而是直接将应用的 Vulkan API 连同 SPIR-V 格式的着色器二进制原封不动地进行序列化封装,顺着 virtio-gpu 踢出沙箱 。 - 宿主机端:macOS 端通过启用了 Venus 扩展的
virglrenderer接收并反序列化这些数据报文,还原成标准的 Vulkan 调用。 - Metal 落地:在管线的最后一米,开源巨作 MoltenVK 粉墨登场,它实时将 Vulkan 的 API 以及 SPIR-V 着色器转译为等效的 Metal Shading Language(MSL)与底层 Metal Draw Calls,由硬件执行渲染 。
- 虚拟机端:Ubuntu 内部的 Mesa 驱动(
路径客观评价: 毫无疑问,Venus 的引入大幅缩减了渲染链路的冗余度,使得在 Apple Silicon 上运行 3D 图形变得基本可用,甚至是可接受的 。然而,这套依靠层层外挂库转译的开源拼图依然面临操作系统底层的阻抗不匹配。例如,Venus 在 Linux KVM 设计中高度依赖特定内存属性(如 VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT)以实现宿主机和虚拟机之间的 dma-buf(直接内存访问缓冲)内存映射共享,而这些特性在 macOS 的内存管理模型中极度水土不服,致使在某些纹理交互密集型场景下性能仍会受到显著制约 。
技术路径二:Apple 原生半虚拟化图形框架(PVG)
既然通过通用化标准进行层层指令转译存在无可挽回的性能损耗,Apple 利用自身不仅掌控芯片底层硬件,更掌控全套操作系统源代码的优势,构建了一条充满“霸权主义”却极致高效的技术通道:Paravirtualized Graphics (PVG) 原生框架。这项技术被全面应用于基于 Apple Virtualization Framework (AVF) 的产品中,如 Parallels Desktop 和 macOS 自带的虚拟机 API 。
底层逻辑:从源头重塑渲染管线,抹除 API 转译
PVG 的设计理念可以用“破壁直通”来形容。Apple 工程师不再试图在宿主机上模拟、解析复杂的 Linux 通用图形请求,而是直接将“触手”伸进了 Linux 的身体里。
- 特制驱动的“木马”式植入(Guest-side): Apple 官方逆向向 Linux 内核的 DRM 子系统和开源 Mesa 3D 代码库中,贡献了一套专为 Apple 虚拟化量身定做的原生驱动模块(如
apple-gfx-pci以及配合 Asahi Linux 项目开发的衍生框架) 。 当 Ubuntu 内的软件调用图形 API 时,这个特制的 Mesa 驱动在虚拟机内部就已经完成了绝大部分粗活。它清楚地知道自己寄生于一个底座是 Apple Metal 引擎的虚拟环境中,因此驱动在客居态内直接将渲染意图打包成一种极为贴近系统底层语义的高度优化上下文 。 - PVG 框架的直接下发(Host-side): 在 macOS 宿主机层,AVF 通过
ParavirtualizedGraphics.framework暴露了两个核心的底层描述符:PGDeviceDescriptor和PGDisplayDescriptor。这一层充当了一个绝对通畅的传送门。 Linux 虚拟机内部处理好的图形指令状态,通过 Apple 设计的专用 MMIO 或 PCI 后门通道跨过 Hypervisor 边界,瞬间抵达ParavirtualizedGraphics.framework。宿主机的这个框架此时几乎不承担任何繁重的 API 重翻译工作,而是直接将其封装为底层的 Metal Command Buffer,一股脑地倾泻给 M 芯片的 GPU 管线。
M 芯片 UMA 架构下的终极性能爆发
PVG 技术真正的杀手锏在于它对 Apple 芯片 Unified Memory Architecture (UMA) 的完美利用。在传统虚拟化中,最大的开销之一是将数据从虚拟机的 RAM 拷贝到宿主机的显卡显存中。但由于 M 芯片的 CPU、GPU 和 NPU 共享同一块物理内存晶圆,AVF 虚拟化框架允许直接打通物理内存映射机制 。 在 PVG 框架下,Linux 虚拟机为纹理和帧缓冲分配的内存页表,在宿主机侧直接被 Metal 引擎以纹理资源的身份识别。这意味着当 Ubuntu 内发生极其复杂的 3D 模型纹理渲染时,底层数据实现了真正物理意义上的“零次数据拷贝与搬运” 。因此,在这种半虚拟化原生的加持下,开发者甚至能在虚拟机内体验到几乎与宿主机 Native 执行别无二致的丝滑帧率与低至极致的硬件功耗 。
3.3 本地虚拟化场景技术选型客观建议
基于上述对 QEMU (Venus) 转译体系与 Apple 原生 PVG 框架底层剖析,针对不同需求的系统开发者,以下是基于投入产出比与性能极限考量的技术选型建议:
| 评估维度 | virtio-gpu + Venus 翻译官方案 (开源 QEMU 体系) | 原生 Paravirtualized Graphics (AVF 体系) |
|---|---|---|
| 底层转换层级 | 极度深沉复杂 (Guest Vulkan -> Venus -> MoltenVK -> Metal) | 极为扁平直接 (Guest 专有 Mesa 驱动直击底层 -> PVG -> Metal) |
| 系统资源消耗与损耗 | 中等到偏高 (大量 CPU 算力被消耗在序列化拆包与协议层层翻译中) | 极低 (受惠于直接映射与底层 UMA 架构的物理级零拷贝机制) |
| 环境自由度与生态兼容 | 极高 (完全开源,数据流完全可控,可移植性强,适合研究内核通讯机制) | 严格受限 (紧锁 Apple 封闭生态,强依赖 AVF 专有框架与受限版本环境) |
| 整体 3D 渲染表现 | 一般,应对部分着色器复杂的重度场景易发生降频甚至崩溃 | 顶级,帧率表现可与原生环境下的直接硬件调用并驾齐驱 |
-
轻量级系统运维与常规代码开发:
如果日常工作仅仅是在 Linux 虚拟机中运行 VS Code Server、基础的终端交互(Terminal)以及浏览轻量级网页,这类 2D 任务对 GPU 算力的需求可以说是微乎其微。开发者大可直接使用最基础的 Virtio 图形配置甚至不带 3D 渲染,凭借 M 芯片强劲的 CPU 进行软件层面的算力托底(Software Rasterizer)。此时,即便是利用 RDP 或 VNC 进行简单的跨平台调用也能获得足够清晰流畅的编码体验,完全无需为了强行追求图形管线的开启而耗费精力配置驱动。
-
跨平台图形堆栈研究与开源驱动底层调试:
如果您的身份是一位专注于钻研 Linux 渲染驱动、Wayland 协议合成器原理,或者是深入探索 Vulkan API 执行流转过程的系统工程师,基于 QEMU 与 virtio-gpu (Venus) 的全开源方案是不可多得的无价实验田。这套架构由于没有闭源黑盒的干扰,允许开发者在协议栈的每一层插入探针(Probe),监控数据包在虚拟机与宿主环境之间的序列化特征,这对于学术研究和开源内核驱动的逆向开发具有巨大的价值。
-
重度 3D 物理仿真开发与人工智能图像渲染推断:
对于必须在 Linux 虚拟机中运行诸如 ROS2(机器人操作系统)、Gazebo 3D 物理引擎、复杂 CAD 建模软件,或借助 GPU 的 Vulkan 计算能力去跑动 Llama 深度学习本地大模型推断的硬核开发者而言,任何一丝指令转译的延迟与内存拷贝的损耗都是致命的。在面对这等极限负载时,强依赖 Apple AVF 架构的 PVG 原生半虚拟化框架是唯一且不二的技术选项。唯有通过这条抛弃一切累赘中间层的直达通道,才能释放并榨干 M 系列芯片统一内存架构的全部算力红利,确保复杂仿真不仅不崩溃,更能维持稳定顺滑的工业级渲染表现。
全文总结
从广袤无垠的物理网络传输到严密受限的本地沙箱,从诞生于数十年前的宏大 X11 网络透明理想,到今日 Apple 凭借芯片垄断力量构建的绝对软硬一体闭源管线,图形界面显示与虚拟化技术的发展脉络,是一部在底层指令兼容性、数据带宽压缩比、异构进程隔离度以及渲染硬件能效比这四个多维变量间不断拉扯与妥协的浩瀚工程史。
无论是试图通过传递抽象线条描绘锐利代码的 RDP 协议,凭借最原始脏矩形像素包容万物的 VNC,利用狂暴物理硬件完成毫秒级编码推流的 Moonlight,还是竭尽全力抹平不同 OS 之间图形 API 阻隔的 Venus 翻译管线与 Apple PVG 框架——它们都没有绝对的高下之分,仅是对特定工业场景所做出的精妙帕累托最优解。深刻洞悉并敬畏这些横亘于异构系统底层深处的架构哲理与技术壁垒,将赋予系统架构师在面对未来更加错综复杂的云计算与边缘协同开发环境时,一击切中核心矛盾并制定精准技术战略的底气与远见。
Powered by Astro & Fuwari
粤ICP备2026022762号-1
 粤公网安备44011202003680号
粤公网安备44011202003680号